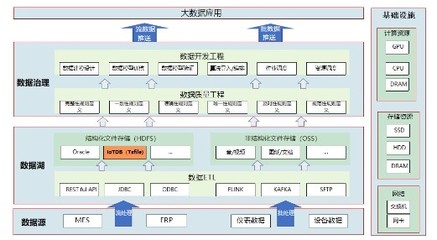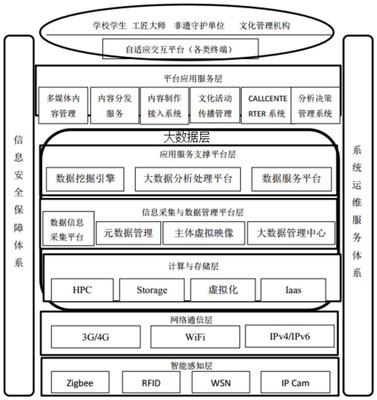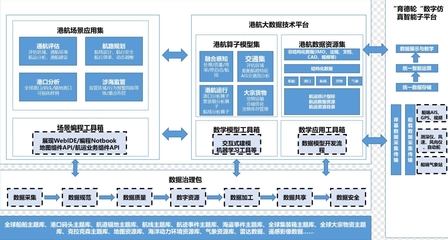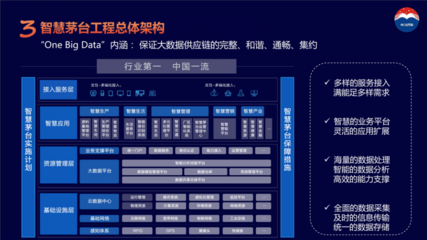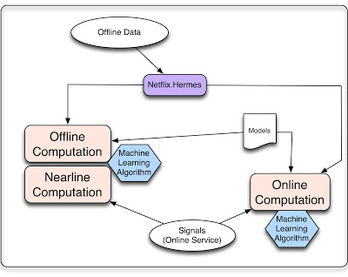
Netflix分享了其支撑全球数亿用户体验的个性化与推荐系统核心架构,揭示了其如何通过三种关键类型的作业,构建起一套高效、实时的数据处理和存储支持服务体系。这套体系不仅是其内容精准分发的基石,也是其用户留存与商业成功的关键引擎。
一、系统核心:三种作业类型协同作战
Netflix的架构核心围绕三种数据处理作业精心设计,确保从用户行为到个性化推荐的端到端流程既实时又可靠。
- 实时流处理作业: 这是系统的“神经末梢”。它持续监听用户的各种实时互动,如播放、评分、搜索、浏览等。利用Apache Kafka等流处理平台,这些事件被即时捕获、处理并转化为低延迟的更新信号,直接注入在线推荐模型,确保用户眼前的推荐结果能够迅速反映其最新兴趣。例如,用户刚看完一部科幻片,系统便能近乎实时地在“为你推荐”栏位中增加同类内容。
- 近实时批处理作业: 扮演着“周期性整理与深化”的角色。通过Apache Spark等大规模数据处理框架,系统以分钟或小时为周期,对海量的用户行为数据进行聚合、分析与特征工程。这些作业计算更复杂的用户画像(如长期兴趣偏好、内容品类亲和力)和内容特征,为模型训练和深度推荐提供高质量、结构化的输入数据。它平衡了计算深度与时效性。
- 离线批处理与模型训练作业: 这是系统的“大脑训练营”。在拥有强大计算资源的云端(如AWS),Netflix运行着大规模的离线作业。这些作业处理历史全量数据,进行深度数据挖掘、A/B测试结果分析,以及最关键的任务——训练和迭代复杂的机器学习推荐模型(如深度学习排序模型)。训练好的新模型经过验证后,再部署到线上服务中。
二、实时数据处理与存储的支撑服务
为了支持上述三类作业高效运行,Netflix构建了多层级的存储与数据服务架构。
- 分层存储体系:
- 高速缓存层(如Memcached, Redis): 存储最热门的用户特征、模型参数和实时计算结果,为在线API提供微秒级的响应。
- 在线存储层(如Cassandra, Dynomite): 存储用户最近的行为会话、实时更新的个人状态,支持高并发、低延迟的读写。
- 近线/离线存储层(如S3, Hive): 使用对象存储和数据仓库,持久化保存所有原始事件日志、处理后的特征数据集以及模型训练所需的海量历史数据,成本低廉且可扩展性极强。
- 统一数据管道与服务化: Netflix通过自研的“数据管道即服务”平台,将数据的生产、消费、治理和发现流程标准化。这使得不同团队(如推荐算法、内容理解、实验平台)能够便捷、可靠地访问所需数据,无论是实时流、批处理表还是特征值,加速了创新迭代。
- 实时索引与搜索支持: 为了快速响应用户搜索和基于内容的过滤,系统维护着内容的实时索引。当新内容上线或元数据变更时,通过流处理作业即时更新索引,确保推荐和搜索结果的 freshness。
三、架构价值与挑战
这种架构设计的最大优势在于 “分层处理,各司其职” 。实时流确保了即时性,近线批处理保证了效率与深度的平衡,离线训练则专注于模型的最优性。三者通过统一的数据总线和管理服务紧密衔接,形成了从“秒级”到“天级”的完整数据闭环。
这也带来了复杂性挑战,包括跨层数据一致性的维护、作业依赖关系的管理、资源成本优化以及确保整个系统在面对峰值流量时的弹性与可靠性。Netflix通过持续的云原生架构演进、自动化运维以及强大的数据监控文化来应对这些挑战。
###
Netflix公布的这套架构,清晰地展示了一个世界级的个性化系统如何将实时性、规模性与智能性融为一体。三种作业类型的划分与协同,以及背后坚实的数据处理与存储支持服务,共同织就了一张精准理解用户、智能连接内容的无形之网,持续驱动着其娱乐帝国的用户体验与增长。这不仅是技术实践的典范,也为业界在构建大规模实时智能系统方面提供了宝贵的参考蓝图。